ITILとは?初心者でもわかるIT用語解説 | 基本情報技術者試験対策
oufmoui
TAKE IT EASY!


SQLはデータベースを操作するための言語で、基本情報技術者試験では頻出の分野です。初心者にとっては難しく感じるかもしれませんが、基本を理解すれば十分に対応できます。
この記事では、SQLの基本概念から試験での出題傾向、効果的な学習方法、さらには練習問題まで、初心者の方にもわかりやすく解説します。
SQLは単なる暗記ではなく、実際にどのようにデータベースを操作するのかをイメージできるようになることが大切です。この記事を読み終える頃には、SQLの基本を理解し、基本情報技術者試験対策にも自信がついているはずです。
ここでは、SQLとは何か、どんな場面で使われるのか、そしてIT業界でどのような位置づけなのかを解説します。SQLの全体像を掴み、関連する用語との違いも明確にしていきましょう。
私たちの周りは、気づかないうちにたくさんの「データ」で溢れています。普段使っているSNSの投稿や友達リスト、ネットショッピングの商品情報や購入履歴、会社の顧客リストや在庫数など、これらすべてが「データベース」と呼ばれる場所に整理されて保存されています。
そして、そのデータベースに「この情報を見せて!」「新しい情報を追加して!」「この情報を更新して!」とお願いするための共通の言葉、それがSQL(エスキューエル、シークェル)なんです。
SQLは、Structured Query Language の略で、日本語に訳すと「構造化問い合わせ言語」となります。でも、この訳語を覚える必要はありません。もっとシンプルに、「データベースとお話しするための専用の言葉」と考えてください。
SQLのルーツは、1970年代にIBM社が開発した「System R」という世界初のリレーショナルデータベース管理システム(RDBMS)とその操作言語「SEQUEL(Structured English Query Language)」にあります。その後、名称がSQLとなり、広く使われるようになりました。
SQLの大きな特徴は、ISO(国際標準化機構)などによって言語の仕様が標準化されていることです。これは非常に重要で、Oracle Database, MySQL, SQL Server, PostgreSQLといった異なるデータベース製品でも、ほぼ同じSQL文を使って操作できることを意味します。
つまり、一度SQLを学べば、様々なシステムや環境でその知識を活かせる、汎用性の高いスキルなのです。この「標準化されている」という事実が、SQLが長年にわたってIT業界の基盤技術として使われ続け、今なお高い需要がある理由の一つです。
SQLを理解するには、まず「データベース」について知る必要があります。
データベース (DB) とは?
データベースとは、簡単に言うと「整理された情報の集まり」のことです。例えば、住所録、電話帳、図書館の本のリストなどもデータベースの一種です。コンピュータの世界では、これらの情報を効率的に管理・利用できるようにしたシステム全体を指すことが多いです。Excelのファイル(ブック)にたくさんのシートがあり、それぞれに情報が整理されている様子をイメージするとわかりやすいかもしれません。
データベース管理システム (DBMS) とは?
データベースを効率よく管理・運用するためのソフトウェアのことです。データの追加、検索、更新、削除などの機能を提供します。MySQLやPostgreSQLなどが有名です。
リレーショナルデータベース (RDB) とは?
SQLが主に活躍するのは、このリレーショナルデータベース(RDB)という種類のデータベースです。RDBは、データを「テーブル」と呼ばれる表形式で管理するのが最大の特徴です。Excelのシートのようなものを想像してください。
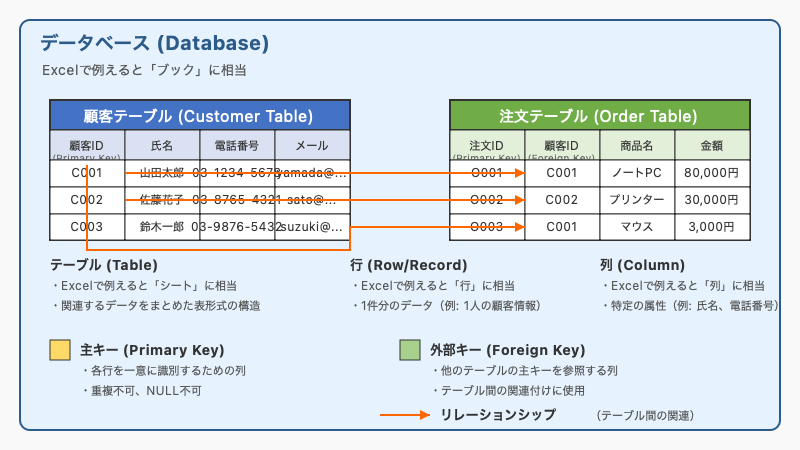
主な要素は次の通りです。
では、具体的にSQLはどんな場面で使われているのでしょうか?
SQLは、現代のITシステムにおいてデータを扱うための基盤技術であり、その重要性は非常に高いです。
幅広い職種で求められるスキル: データベースエンジニアはもちろんのこと、Webアプリケーションを開発するサーバーサイドエンジニア、データを分析するデータサイエンティスト、システムの基盤を支えるインフラエンジニアにとってもSQLは必須または重要なスキルです。さらに、マーケターや企画担当者といった非エンジニア職であっても、SQLを扱えることでデータに基づいた分析や意思決定が可能になり、業務の幅が広がります。
高い需要と将来性: SQLは1970年代に生まれた比較的古い技術ですが、その重要性は今も全く衰えていません。むしろ、AWSなどのクラウドサービスの普及、ビッグデータの活用、AI(人工知能)やIoTといった先端分野においても、データを効率的に扱うためのSQLスキルは不可欠であり、その需要は増しています。
NoSQLのような新しいデータベース技術も登場していますが、多くのシステムの根幹では依然としてRDBとSQLが使われ続けています。これは、RDBが持つデータの整合性を保つ仕組みや、SQLによる柔軟なデータ操作能力が、多くの業務要件に適しているためです。
クラウド環境でも標準的にRDBが利用されており、その操作にはSQLが必須です。また、データ分析の重要性が高まる中で、データを抽出・集計するための言語としてのSQLの役割はますます大きくなっています。
このように、技術トレンドが変化する中でも、SQLの「データを構造的に扱う」という基本的な考え方とスキルは応用範囲が広く、普遍的な価値を持ち続けているのです。そのため、SQLスキルは市場価値が高く、就職や転職においても有利に働きます。
初心者が混同しやすい用語との違いを明確にしておきましょう。
SQL vs プログラミング言語 (Java, Pythonなど):
SQL vs DBMS (MySQL, PostgreSQLなど):
【表1: SQLとプログラミング言語の違い】
| 特徴 | SQL (データベース言語) | プログラミング言語 (Java, Pythonなど) |
|---|---|---|
| 目的 | データベースの操作に特化 | アプリ開発、計算、自動化など汎用的な処理 |
| できること | データの定義、検索、追加、更新、削除、権限管理 | 幅広い処理(条件分岐、繰り返し、ファイル操作、画面表示など) |
| 使い方 | 単独で対話的に実行、またはプログラムに埋め込む | 主にプログラムを作成して実行する |
| 記述方法 | 宣言的(何が欲しいかを記述)、対話的 | 手続き的(処理の手順を記述) |
この表を見ると、SQLとプログラミング言語がそれぞれ異なる役割を持っていることがよく分かりますね。SQLはデータ操作のエキスパート、プログラミング言語はより広範な処理を担当する、というイメージです。この違いを理解することで、SQLの学習範囲や、プログラミング学習との関連性が見えてきます。
基本情報技術者試験(FE試験)で、SQLがどれくらい重要なのか、どんな問題が出るのかを解説します。過去問の傾向を知り、効率的な試験対策のポイントを掴みましょう。
基本情報技術者試験においてデータベース分野は非常に重要な分野の一つとして位置づけられています。中でもSQLは、データベースの操作言語として中心的な役割を担っており、試験でも多くの問題が出題されます。
FE試験では、SQLに関する問題が一定数出題されます。具体的な出題状況を見てみましょう。
科目A(旧午前試験): データベースに関する問題が複数問出題され、その中核をなすのがSQLです。データベースの基本的な知識とともに、特にSELECT文(データの検索・抽出)に関する問題が多く出題されます。
科目B(旧午後試験): 2023年度からの新試験制度では、独立したデータベース選択問題はなくなりました。しかし、科目Bで出題されるアルゴリズムやプログラミングの問題において、データベースを操作する場面は依然として考えられ、SQLの基本的な考え方やデータ構造の理解は間接的に役立ちます。
また、FE試験の合格だけでなく、その先の応用情報技術者試験やデータベーススペシャリスト試験を目指す上でも、SQLは必須の知識となります。
なぜFE試験でSQLがこれほど重視されるのでしょうか?それは、現代のITシステムの多くがデータベースを基盤としており、その操作言語であるSQLはITエンジニアにとって必須の基礎知識だからです。
また、SQLの問題は基本的な構文や考え方を理解していれば比較的得点しやすく、安定した得点源にできる可能性が高い分野でもあります。したがって、SQLを苦手なまま放置せず、基本をしっかり押さえておくことが、FE試験合格のための重要な戦略となります。
FE試験のSQL問題は、過去に出題された問題と類似した形式・内容の問題が繰り返し出題される傾向があります。そのため、過去問演習が非常に効果的な対策となります。
具体的にどのような内容が出題されやすいか見ていきましょう。
最重要! SELECT文: データの検索・抽出を行うSELECT文に関する問題が圧倒的に多く、最重要項目です。
基本的なDML (データ操作言語):
基本的なDDL (データ定義言語) と DCL (データ制御言語):
トランザクション管理:
データベース設計の基礎:
過去問を分析すると、非常に複雑で難解なSQLが要求されるというよりは、基本的なSQL構文を正しく理解し、問題文で与えられたテーブル構造と要求(何を取得したいか)を正確に読み取って、適切な構文を組み立てる能力が試されていることがわかります。
特にWHERE句での条件指定、JOINでのテーブル結合、GROUP BYでの集計といった頻出パターンを確実にマスターすることが、得点への近道です。
FE試験(特に科目A)では、主に以下のような形式でSQLの知識が問われます。
SQL文そのものだけでなく、以下の関連知識も合わせて理解しておくことが重要です。
これらの分類と代表的なコマンドを覚えておく必要があります。
ここでは、SQLの主要な命令やデータベース操作について、図や具体的な例を使ってさらに詳しく解説します。初心者が間違いやすいポイントや、実際の仕事でどう役立つのかも見ていきましょう。
SQLは実際に使ってみると、思ったより簡単で直感的な言語だということがわかります。まずは基本的な構文と操作について理解を深めていきましょう。
文章だけではイメージしにくい概念も、図や表を使うと理解が深まります。
リレーショナルデータベース (RDB) の構造:
データベースの中に複数の「テーブル」があり、各テーブルは「行(レコード)」と「列(カラム)」で構成されます。テーブル間は「主キー」と「外部キー」によって関連付けられます。
SELECT文の処理順序(概念)
SQL文は書かれた順番通りに処理されるわけではありません。一般的に、データベース内部では次のような順序で処理が進むと考えられています(厳密な処理はDBMSによります)。
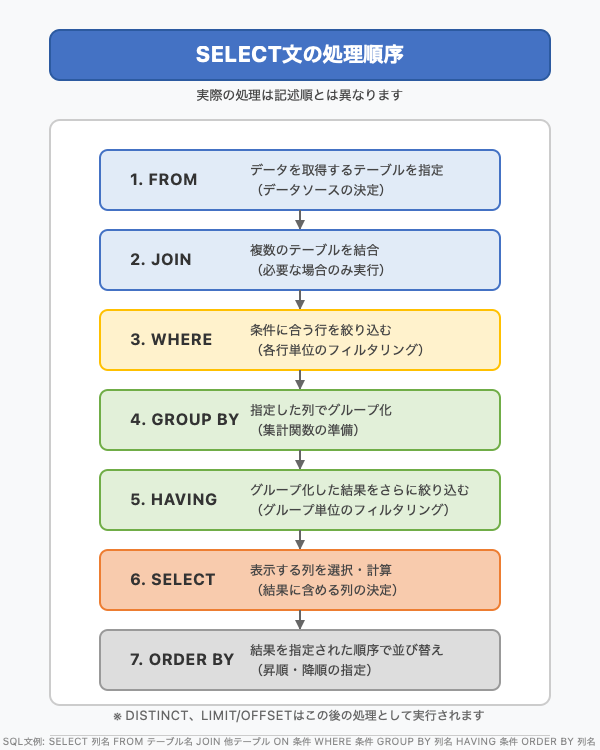
この流れを意識すると、WHEREとHAVINGの違いなどが理解しやすくなります。
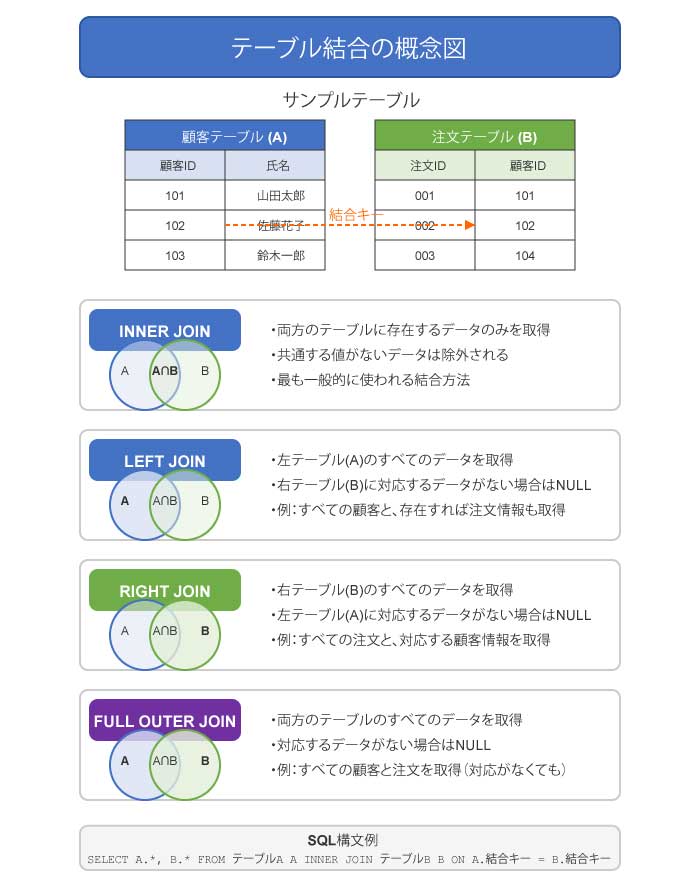
テーブル結合 (JOIN) のイメージ:
例えば、「注文テーブル」と「顧客テーブル」があるとします。注文テーブルには「顧客ID」がありますが、顧客の名前はありません。顧客テーブルには「顧客ID」と「顧客名」があります。この二つのテーブルを「顧客ID」で紐づける(結合する)ことで、「どの注文が、どの顧客からのものか」を一覧表示できます。これがINNER JOIN(内部結合)の基本的な考え方です。
【表2: SQLの主な命令(DDL, DML, DCL)】
SQLの命令は、その役割によって大きく3つに分類されます。
| 分類 | 目的 | 主な命令 |
|---|---|---|
| DDL (データ定義言語) | データベースやテーブルの構造を定義する | CREATE (作成), ALTER (変更), DROP (削除) |
| DML (データ操作言語) | テーブル内のデータを操作する | SELECT (検索), INSERT (追加), UPDATE (更新), DELETE (削除) |
| DCL (データ制御言語) | データへのアクセス権限などを制御する | GRANT (権限付与), REVOKE (権限剥奪) |
FE試験では特にDML、中でもSELECT文が中心ですが、DDLやDCLの基本的なコマンドも問われることがあるため、それぞれの役割と代表的な命令を覚えておきましょう。
実際の場面を想定して、SQL文を見てみましょう。
ケース1: ECサイトの商品検索
SELECT
T1.商品名, -- 商品テーブルから商品名を取得
T1.価格 -- 商品テーブルから価格を取得
FROM
商品テーブル AS T1 -- 商品テーブルをT1という別名で参照
INNER JOIN
カテゴリテーブル AS T2 -- カテゴリテーブルをT2という別名で参照
ON
T1.カテゴリID = T2.カテゴリID -- 両テーブルをカテゴリIDで結合
WHERE
T2.カテゴリ名 = '食品' -- カテゴリ名が'食品'の行に絞り込み
AND T1.価格 >= 1000 -- かつ、価格が1000円以上の行に絞り込み
AND T1.価格 < 3000 -- かつ、価格が3000円未満の行に絞り込み
ORDER BY
T1.価格 ASC; -- 価格の昇順(ASCending)で並び替えケース2: 社員情報の管理
INSERT INTO 社員テーブル (社員番号, 氏名, 所属部署ID, 入社年月日)
VALUES ('E123', '新人 太郎', 'D02', '2024-04-01');UPDATE 社員テーブル
SET 所属部署ID = 'D01'
WHERE 社員番号 = 'E050';SELECT
T2.部署名,
COUNT(T1.社員番号) AS 社員数 -- 社員番号をカウントし、社員数という別名をつける
FROM
社員テーブル AS T1
INNER JOIN
部署テーブル AS T2 ON T1.所属部署ID = T2.部署ID
GROUP BY
T2.部署名; -- 部署名でグループ化DELETE FROM 社員テーブル
WHERE 入社年月日 < '2020-01-01';SQLを学び始めると、似たような機能を持つ命令や概念で混乱することがあります。代表的なものを整理しておきましょう。
WHERE句とHAVING句の違い:
どちらもデータを絞り込むための条件を指定しますが、処理されるタイミングが異なります。
覚え方: 「WHEREは元のデータにかけるフィルター、HAVINGは集計結果にかけるフィルター」
DELETEとDROP TABLEの違い:
COUNT(*)とCOUNT(列名)の違い:
どちらも行数を数える集計関数ですが、NULL値の扱いが異なります。
文字列と数値の扱い:
SQLではデータ型が重要です。特にWHERE句などで値を比較する際、文字列は通常’(シングルクォーテーション)で囲む必要があります(例: WHERE 氏名 = ‘山田 太郎’)。数値は囲みません(例: WHERE 年齢 = 30)。DBMSによってはダブルクォーテーションが使える場合もありますが、シングルクォーテーションが標準的です。
NULLの扱い:
NULLは「値が存在しない」ことを示す特殊な状態です。ゼロ(0)や空文字列(”)とは異なります。
これらの違いをしっかり理解し、使い分けられるように練習しましょう。
SQLは試験のためだけの知識ではありません。実際の仕事の様々な場面で活用される、非常に実践的なスキルです。
データ抽出・レポート作成: 営業部門が「今月の売上トップ10の商品リスト」を作成したり、マーケティング部門が「特定のキャンペーンに参加した顧客の属性別リスト」を抽出したり、Web担当者が「アクセス数の多いページのランキング」を作成したりする際に、SQLが使われます。必要なデータをデータベースから素早く正確に取り出し、ビジネス上の意思決定に役立てます。
システム開発の裏側: ユーザーがWebサイトで会員登録ボタンを押すと、裏側ではINSERT文が実行されて会員情報がデータベースに登録されます。ログイン時にはSELECT文でユーザー情報を検索し、マイページで情報を変更するとUPDATE文が実行されます。このように、アプリケーションがデータベースと連携する処理の多くでSQLが動いています。
データメンテナンス: 長期間使われていない古いアカウント情報を削除したり(DELETE)、入力ミスで登録された誤った住所情報を修正したり(UPDATE)、新しい商品カテゴリを追加したり(INSERT)と、データベース内のデータを常に正確で最新の状態に保つための作業にもSQLが使われます。
データ移行: 古いシステムから新しいシステムへデータを引っ越しさせる際にも、旧システムからSQLでデータを抽出し、必要に応じて加工してから新システムへINSERTするといった作業が行われることがあります。
特に、エンジニア以外の職種の方がSQLスキルを身につけるメリットは大きいです。これまではデータが必要になるたびにエンジニアに抽出を依頼し、待たなければならなかった場面でも、自分で直接データベースにアクセスし、必要な情報をすぐに手に入れられるようになります。
これにより、分析のスピードが上がり、データに基づいた企画立案や改善提案がしやすくなるなど、仕事の質と効率を大きく向上させることが期待できます。SQLは、職種を問わず、データに基づいたより良い働き方を実現するための強力な武器となるのです。
FE試験のSQL問題で確実に得点するための、効果的な学習方法や暗記のコツ、注意点などを具体的にアドバイスします。これを読めば、独学でも効率よく対策を進められますよ。
SQLは基本情報技術者試験において重要な出題分野の一つです。効率的に学習して確実に得点できるようにしましょう。
やみくもに勉強するのではなく、ポイントを押さえて効率よく学習を進めましょう。
① 基本構文をしっかり理解する:
まずは、データ操作の基本であるSELECT, INSERT, UPDATE, DELETEの4つの命令(DML)の基本的な書き方と意味を確実に理解しましょう。特にSELECT文は最重要です。FROM, WHERE, GROUP BY, ORDER BYといった主要な句がそれぞれ何をするためのものなのか、基本的な使い方をマスターしてください。
② 実際に書いて動かす!:
参考書や解説記事を読むだけでは、SQLはなかなか身につきません。一番大切なのは、実際に自分でSQL文を書いて、実行してみることです。自分のパソコンに無料で使えるデータベース(SQLiteやPostgreSQL、MySQLなど)をインストールしても良いですし、Webブラウザ上で手軽に試せるオンラインのSQL実行環境(例えば、paiza.IO や W3Schools SQL Tryit Editor など)を利用するのもおすすめです。簡単なSELECT文から始めて、少しずつ複雑な条件や関数を試していくことで、文法や挙動が体感的に理解できるようになります。
「ここに[SQL練習サイト]への外部リンク設置」
③ 過去問演習を繰り返す:
FE試験対策としては、過去問題(特に科目A/旧午前試験)を繰り返し解くことが非常に効果的です。FE試験では過去に出題された問題と類似の問題が何度も出題される傾向が強いからです。問題を解くだけでなく、間違えた問題については、なぜ間違えたのか、正解の選択肢はなぜ正しいのかを解説を読んでしっかり理解することが重要です。理解できるまで、類似の問題を探して解いてみるのも良いでしょう。
SQLのすべての機能を網羅的に学ぶのは大変ですが、試験に出やすいパターンはある程度限られています。過去問を通して、その頻出パターンと問われ方を集中的に学習するのが、合格への最短ルートと言えます。
④ 図解やイラストを活用する:
リレーショナルデータベースの構造(テーブル、行、列、キーの関係)や、SELECT文の処理の流れ、JOINの仕組みなどは、文章だけでなく図やイラストでイメージを掴むと記憶に残りやすくなります。分かりやすい図解が載っている参考書やWebサイトを積極的に活用しましょう。
⑤ 声に出して読んでみる:
意外な方法かもしれませんが、SQL文、特にSELECT文の句の連なり(SELECT… FROM… WHERE… GROUP BY… ORDER BY…)などを声に出して読んでみると、構文のリズムや構造が頭に入りやすくなることがあります。
丸暗記は推奨しませんが、覚えておくと便利なポイントや語呂合わせを紹介します。
SELECT文の主要な句の順序:
SELECT → FROM → WHERE → GROUP BY → HAVING → ORDER BY
この基本的な順序は決まっています。「セフロム 上野 グルッと ハブって オダバイ」のように、自分なりの語呂合わせを作って覚えるのがおすすめです。(※ FROMとWHEREの間などにJOINが入ることもあります)
DDL, DML, DCL の分類:
それぞれの頭文字と日本語の意味を結びつけましょう。
よく使う集計関数:
COUNT (件数), SUM (合計), AVG (平均), MAX (最大値), MIN (最小値) はセットで覚えてしまいましょう。
主キー (Primary Key) のイメージ:
「クラスの名簿の出席番号」や「会社の社員番号」のように、「絶対に他の人(行)とかぶらず、その人(行)を特定できる唯一の番号」という具体的なイメージを持つと分かりやすいです。
混乱しやすい概念は、違いを明確に意識して区別しましょう。
WHERE vs HAVING:
前述の通り、「グループ化の前か後か」で区別します。「元の表の各行に対する条件」ならWHERE、「グループ化して集計した結果に対する条件」ならHAVINGです。練習問題で具体例を確認するのが一番です。
DELETE vs DROP TABLE:
これも前述しましたが、「テーブルの中身(データ行)だけ消す」のがDELETE、「テーブルそのもの(箱ごと)を消す」のがDROP TABLEです。影響範囲が全く異なります。
内部結合 (INNER JOIN) vs 外部結合 (LEFT JOIN, RIGHT JOIN):
FE試験では、まずは基本となる内部結合をしっかり理解することが重要です。外部結合は、内部結合との違い(片方のテーブルにしかないデータも残すかどうか)を意識して学習しましょう。
効率的に学習を進めるためのステップと、独学者向けのアドバイスです。
学習ステップ:
時間配分:
SQLはFE試験の中でも重要な分野なので、全体の学習時間の中でも優先度を高めに設定することをおすすめします。特に、ステップ2(SELECT基本)、ステップ4(SELECT応用)、ステップ6(過去問演習)には十分な時間をかけましょう。
独学者へのアドバイス:
一人で学習していると、どうしても分からない点や疑問点が出てくるものです。そんな時は、Web上の解説記事(本記事のような!)や、技術系のQ&Aサイト、学習フォーラムなどを積極的に活用しましょう。一つの問題で長時間悩み続けるよりも、基本に立ち返って簡単なSQL文を書いてみたり、別の資料をあたってみたりする方が、結果的に早く解決できることもあります。諦めずに、少しずつでも前に進むことが大切です。
ここまで学んだ知識を試してみましょう!基本情報技術者試験で出題されそうなレベルのSQL練習問題をいくつか用意しました。詳しい解説付きなので、力試しと復習に役立ててください。
学んだ知識を実際に問題を解くことで定着させましょう。ここでは、基本情報技術者試験レベルのSQL問題を解いていきます。
(※ 科目A試験の四肢択一式を想定しています)
問題1
商品テーブル(商品コード CHAR(4) 主キー, 商品名 VARCHAR(50), 単価 INTEGER, 在庫数 INTEGER)がある。単価が500円以上で、かつ在庫数が10個未満の商品コードと商品名を取得するSQL文として、適切なものはどれか。
ア. SELECT 商品コード, 商品名 FROM 商品テーブル WHERE 単価 >= 500 OR 在庫数 < 10; イ. SELECT 商品コード, 商品名 FROM 商品テーブル WHERE 単価 > 500 AND 在庫数 <= 10; ウ. SELECT 商品コード, 商品名 FROM 商品テーブル WHERE 単価 >= 500 AND 在庫数 < 10; エ. SELECT * FROM 商品テーブル WHERE 単価 >= 500 AND 在庫数 < 10;
問題2
注文テーブル(注文番号 INTEGER 主キー, 顧客ID CHAR(5), 注文日 DATE)がある。顧客IDごとの注文件数を取得するSQL文として、適切なものはどれか。
ア. SELECT 顧客ID, COUNT() FROM 注文テーブル; イ. SELECT 顧客ID, SUM(注文番号) FROM 注文テーブル GROUP BY 顧客ID; ウ. SELECT 顧客ID, COUNT() FROM 注文テーブル GROUP BY 顧客ID;
エ. SELECT 顧客ID, COUNT() FROM 注文テーブル WHERE COUNT() > 1 GROUP BY 顧客ID;
問題3
社員テーブル(社員ID CHAR(3) 主キー, 氏名 VARCHAR(30), 部署コード CHAR(2))と部署テーブル(部署コード CHAR(2) 主キー, 部署名 VARCHAR(20))がある。『営業部』に所属する社員の氏名を取得するSQL文として、適切なものはどれか。
ア. SELECT 氏名 FROM 社員テーブル WHERE 部署コード = ‘営業部’;
イ. SELECT T1.氏名 FROM 社員テーブル AS T1 JOIN 部署テーブル AS T2 ON T1.部署コード = T2.部署コード WHERE T2.部署名 = ‘営業部’;
ウ. SELECT T1.氏名 FROM 社員テーブル AS T1 JOIN 部署テーブル AS T2 ON T1.氏名 = T2.部署名 WHERE T2.部署名 = ‘営業部’;
エ. SELECT T2.部署名 FROM 社員テーブル AS T1 JOIN 部署テーブル AS T2 ON T1.部署コード = T2.部署コード WHERE T1.氏名 = ‘営業部’;
問題4
会員テーブルから、最終ログイン日が1年以上前の会員データを削除するSQL命令として、適切なものはどれか。
ア. UPDATE
イ. DROP
ウ. SELECT
エ. DELETE
問題5
リレーショナルデータベースのテーブルにおいて、行(レコード)を一意に識別するために設定される列(カラム)のことを何と呼ぶか。
ア. 外部キー
イ. インデックス
ウ. 主キー
エ. カラム
問題1:正解 ウ
解説: 単価が500円以上 (単価 >= 500) で、かつ在庫数が10個未満 (在庫数 < 10) という2つの条件を満たす必要があるため、ANDで結合します。取得したいのは商品コードと商品名なので、SELECT句で 商品コード, 商品名 を指定します。
ポイント: 問題文の「~で、かつ~」という表現からAND条件を使うこと、「~を取得する」からSELECT句で指定する列を判断します。
誤答:
問題2:正解 ウ
解説: 「顧客IDごと」の注文件数を求めるには、GROUP BY 顧客IDで顧客IDごとにグループ化し、COUNT(*)で行数(=注文件数)を数える必要があります。
ポイント: 「~ごとに集計する」という場合はGROUP BY句と集計関数(COUNT, SUMなど)の組み合わせを考えます。
誤答:
問題3:正解 イ
解説: 社員の氏名は社員テーブルに、部署名は部署テーブルにあります。部署名『営業部』で絞り込むには、両方のテーブルを結合する必要があります。社員テーブルと部署テーブルを共通の部署コードでJOIN(INNER JOINと同じ)し、WHERE句で部署名 = ‘営業部’と条件を指定します。取得したいのは氏名なので、SELECT T1.氏名とします(T1は社員テーブルの別名)。
ポイント: 複数のテーブルにまたがる情報を取得するにはJOINを使います。ON句でどの列をキーにしてテーブルを繋ぐかを正しく指定することが重要です。
誤答:
問題4:正解 エ
解説: テーブルから特定の条件に合うデータ(行)を削除するSQL命令はDELETEです。
ポイント: DMLの各コマンド(SELECT, INSERT, UPDATE, DELETE)の基本的な役割を理解しているかが問われています。
誤答:
問題5:正解 ウ
解説: テーブル内の各行を一意に識別するためのキーは主キー (Primary Key) です。
ポイント: データベースの基本的な用語の定義を理解しているかが問われています。
誤答:
練習問題の誤答選択肢は、初心者が陥りやすい間違いを反映しています。
条件の混同 (ANDとOR, 比較演算子): 問題1のアやイのように、条件を正しく読み取れず、ANDとORを間違えたり、>=(以上)と>(より大きい)、<(未満)と<=(以下)を混同したりするケースです。問題文を注意深く読むことが大切です。
GROUP BYの理解不足: 問題2のアのように、集計関数を使う際にGROUP BYを忘れると、期待したグループごとの結果になりません。
集計関数の誤用: 問題2のイのように、求めるべき集計(件数ならCOUNT)と違う関数(合計ならSUM)を使ってしまうケースです。
JOINの結合条件の誤り: 問題3のウのように、テーブルを結合する際に、関連性のない列同士で結合しようとしてしまうケースです。主キーと外部キーの関係を意識してON句を指定する必要があります。
DML/DDLコマンドの混同: 問題4のイのように、行を削除するDELETEとテーブル自体を削除するDROPを混同するケースです。操作の対象と影響範囲を正しく理解しましょう。
基本用語の混同: 問題5のアのように、主キーと外部キーの役割を取り違えるケースです。用語の正確な意味を覚えましょう。
これらの「よくある間違いパターン」を意識することで、自分が問題を解く際にどこに注意すべきかが見えてきます。なぜその選択肢が間違いなのかを理解することが、同じミスを防ぎ、応用力を高める上で非常に重要です。
FE試験で、もし少し複雑に見えるSQL問題(例えば、サブクエリが使われている、複数のテーブルがJOINされているなど)に出会っても、焦る必要はありません。以下の点を意識して取り組みましょう。
分解して考える: 長いSQL文は、句ごとに分解して考えます。まずFROM句でどのテーブルが使われているかを確認し、次にWHERE句でどのような条件で絞り込んでいるか、GROUP BYでどうグループ化しているか…というように、順を追って処理内容を理解します。
内側から読む(サブクエリの場合): SQL文の中にカッコで括られた別のSELECT文(サブクエリ)がある場合は、まずその内側のサブクエリが何をしているのかを理解します。その結果が外側のSQL文でどのように使われているかを考えます。
処理順序を意識する: 前述したSELECT文の概念的な処理順序(FROM→WHERE→GROUP BY→HAVING→SELECT→ORDER BY)を頭に入れておくと、SQL文全体の動きを把握しやすくなります。
図や簡単なデータでトレースする: 問題文のテーブル定義を元に、簡単なサンプルデータを自分で作ってみて、SQL文がどのようにデータを処理していくかを紙の上などで追いかけてみる(トレースする)のも有効な方法です。
どんな応用問題も、基本の組み合わせで成り立っています。まずは基本的なSQL構文を確実にマスターすることが、応用問題に対応するための最も確実な基礎力となります。
最後に、この記事で学んだSQLの重要ポイントを振り返り、次に何を学ぶべきか、そしてFE試験合格に向けた効率的な学習ロードマップを提案します。ここまでの学習を確実に力に変えましょう!
この記事では、基本情報技術者試験の合格を目指す初心者・独学者の方に向けて、SQLの基本から試験対策までを解説してきました。
重要なポイントをまとめると、以下のようになります。
【重要ポイントまとめボックス】
✅ SQLはデータベースとお話しするための「言葉」!
✅ ISO標準だから、一度覚えればずっと使える!
✅ FE試験ではSELECT文が超重要!過去問を解きまくろう!
✅ 読むだけじゃダメ!実際に書いて動かしてみよう!
✅ SQLができれば、データがもっと身近になる!仕事にも役立つ!
SQLの基本をマスターしたら、さらに理解を深めるために以下の関連知識を学んでいくと良いでしょう。
データベース設計:
高度なSQL:
データベース管理:
NoSQLデータベース: RDBとは異なる思想で設計されたデータベース(例: MongoDB, Redisなど)。どのような特徴があり、どんな場面で使われるのかを知っておくと視野が広がります。
プログラミング言語との連携: Java (JDBC経由) や Python (psycopg2, mysql-connector-pythonなど) といったプログラミング言語から、どのようにSQLを実行してデータベースを操作するのか、具体的なコードを学んでみる。
基本情報技術者試験の合格、そしてその先のスキルアップを見据えた学習ロードマップの例です。
Step 1: SQL基礎固め (この記事の内容): SQLの基本構文、特にSELECT文をしっかりマスターし、簡単なデータベース操作ができるレベルを目指します。FE試験の過去問(SQL関連)を解いて、基本的な問題に対応できる力をつけます。
Step 2: 基本情報技術者試験 合格: SQLだけでなく、テクノロジ系(コンピュータ科学基礎、ネットワーク、セキュリティなど)、マネジメント系、ストラテジ系といったFE試験の全範囲をバランス良く学習し、試験全体の合格を目指します。苦手分野を作らないことが重要です。「ここに[基本情報技術者試験の全体的な学習法]への内部/外部リンクを設置」
Step 3: 実践力向上: FE試験合格後、より複雑なSQL(サブクエリ、外部結合、簡単なウィンドウ関数など)を学習します。自分で簡単なWebアプリケーションを作ってみたり、興味のあるデータをSQLで分析してみたりするなど、実際に手を動かす経験を積むことで、知識が定着し、応用力が身につきます。
Step 4: 応用・専門分野へ: 自分の興味や目指すキャリアパスに合わせて、学習を深掘りします。データベース設計(正規化、ER図)、パフォーマンスチューニング(インデックス活用、SQL改善)、特定のDBMS(MySQL, PostgreSQLなど)の深い知識、あるいはNoSQLデータベースなど、専門性を高めていきます。応用情報技術者試験やデータベーススペシャリスト試験といった上位資格に挑戦するのも良いでしょう。






